Is a spreadsheet a database?
11 February 2021
What does it look like to use Google Sheets as a lightweight relational database? Read about an experiment with this on the Princeton Ethiopian Miracles of Mary (PEMM) project.

Plenty of people use Google Sheets for data curation; what would it look like to use Google Sheets as a lightweight relational database? For the Princeton Ethiopian Miracles of Mary (PEMM) project, led by Wendy Laura Belcher, we had a chance to experiment with this. Our hope was to set the PEMM team up with a solution that they would be able to manage themselves, instead of implementing a custom relational database, which would require developer time to make changes and incur a heavier maintenance cost.
The PEMM project is gathering information on a collection of Ethiopian folktales called the Täˀammərä Maryam (The Miracles of Mary), written from the 1300s through the 1900s in the ancient African language of Gəˁəz (classical Ethiopic), with the goal of answering important questions about dating and story origins, and determining whether there is a particular order or set of stories that typically appear together in manuscripts.
In the first year of dataset curation support from CDH, Wendy and one collaborator worked on a semi-structured text file based on a digitized version of an early catalog of the miracles of Mary. We wanted to get her data into a more structured environment where more collaborators could get involved, there would be checks to ensure accurate data entry, and Wendy could start to do analysis and begin answering her research questions.

Photograph © Rebecca Sutton Koeser, all rights reserved.
In planning meetings, Wendy would say “my data is like this!” gesturing with interleaved fingers — signalling relational, connected information that doesn’t fit in one spreadsheet.
So, we started planning for the move to a set of related spreadsheets; we modeled and designed the data structure similar to the way we would a relational database. The process of discussing and deciding how to model your data is always so valuable! It forces you to make important decisions. I still remember the “aha” moment when we decided to differentiate canonical stories from “story instances”: this made it possible to separate the description and documentation for a story as it appears in a particular manuscript while still linking it to the canonical story it is a version of, when known.
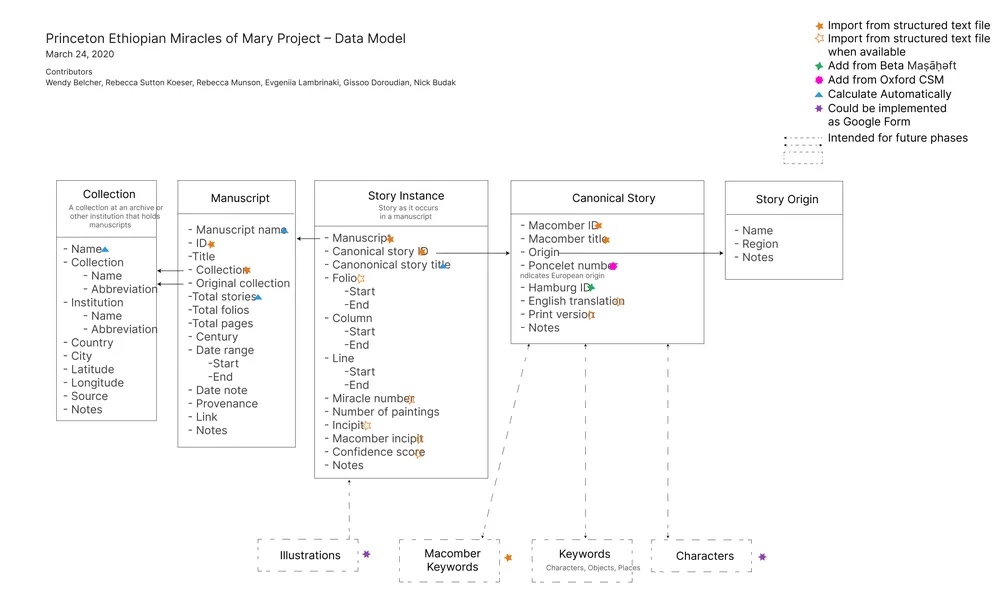
Revised data model diagram for PEMM as of March 2020.
Once the initial data model was settled, we needed to create the spreadsheets in Google Sheets. We could have done this manually, and that probably would have been faster! But we wanted the process to be automated and tested, so we wrote custom code to create the spreadsheets with the structure we had determined. In a relational database, connections between different tables would use database identifiers and what are called “foreign keys”; in our spreadsheets, we used a vertical lookup from another sheet. For example, story instances have lookups to both canonical story and manuscript, so that a particular story can be identified and located without having to duplicate that information in each row.
After the spreadsheet was created and we’d tested that everything was working correctly, I wrote a Python script to parse and convert the data from Wendy’s semi-structured text file into a set of CSV files for import into Google Sheets. As a result, Wendy and her team were able to start working with the data in a new way. Immediately, errors that had not been noticeable in the text file were obvious and easy to correct in the spreadsheet.
Getting the data into Google Sheets didn’t just help with data entry and review. It also meant we could start using the in-progress data with code and tools. We wrote code to regularly pull data from the Google Sheets document in comma-separated format (CSV) for use in an “Incipit Search Tool”, to help the project team identify stories based on the first meaningful lines of the story. Because the tool is regularly updated with data from the spreadsheet, the search results improved as they added more information.
We also wrote a script to synchronize data from Google Sheets to CSV files in a data repository on GitHub. I expected it would be straightforward to synchronize the data, but I was pleased that we were able to get not just the data, but also information about contributors. We use revision information to identify the authors of recent edits, and then include them as co-authors on the git commit. This aligns with CDH values, since we care about giving people credit for their work and being open and transparent about our own work and processes. Having a copy of the data in GitHub provides an open, non-proprietary backup that can be used with other tools as data work moves forward, and also makes it easier to see changes over time by comparing revisions. We set up automatic data checks with GoodTables, and the data could be used for preliminary analysis or display with a static site generator such as Jekyll or Hugo.
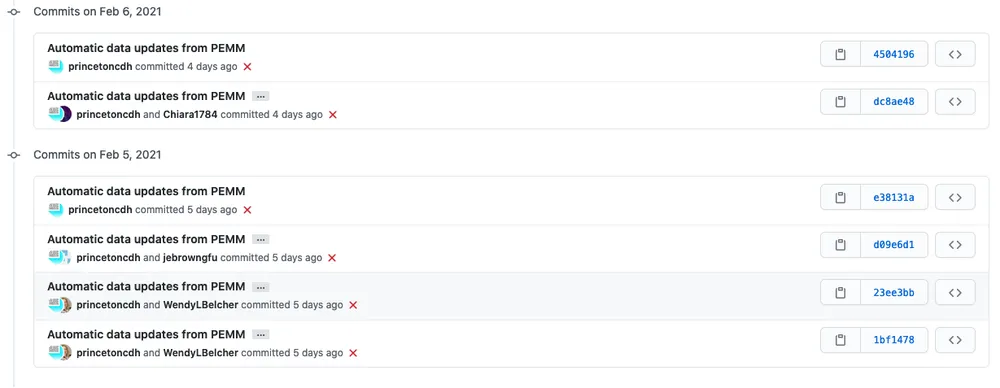
Screenshot of recent commit history for synchronized PEMM data on GitHub showing updates with co-author attribution.
Ultimately, the experiment provided many benefits to the project. Since we successfully transitioned Wendy and her project data into Google Sheets, she’s been able to recruit more collaborators, make significant progress on her project, and begin to do some preliminary analysis. But from the technical side, I’m not sure that this experiment with Google Sheets was a complete success.
Lessons learned
I had hoped we would be able to build “light-weight” tooling around Google Sheets, but because we were doing something new and experimental, we had to figure out and build all those tools ourselves. As we worked on it, we discovered that we had assumptions based on our previous work implementing relational databases that didn’t hold up here.
One big gap was making changes to the spreadsheet after it was in use. When we work with the Django web framework, we can write data migrations to automate the process of adding and modifying fields in the database after it’s already in use, and also to run automatic transformations on the data (e.g., to add new values calculated on existing information, or adjust the data). We didn’t have anything like that for Google Sheets!
Our initial solution to set up and structure the Google Sheets document was something that DH Developer Nick Budak developed in Google Apps Script using the Google Sheets API, and adding migration and data structure versioning seemed wildly out of scope for our proposed “light-weight” solution. So, when we did have to add new fields or adjust validation (as inevitably happens once you start doing real data work), we found ourselves making some changes manually alongside partially-automated changes.
Another assumption we had is that the spreadsheet should be used for primary project data only. It didn’t occur to us that the project team would want to use the same spreadsheet for experimental fields, preliminary analysis, etc, so we never asked them not to do that. To us, that would logically happen in a different spreadsheet! We don’t typically put fields like that directly in our databases; instead we generate data exports to support project team members doing their analysis and experimentation elsewhere. Of course, the whole point of using a spreadsheet instead of a full-fledged database was to give the project team power to manage the data themselves and add fields if necessary—without requiring developer time to implement and test changes to the database. We just never agreed on what the scope of those changes should be.
The project team’s approach to automated data checks was another surprise to us. As a developer, I want automated checks to pass, whether it is data validation in a spreadsheet or automated testing on the software I write, and I want those tests and checks passing even when the work is in progress. We configured in-spreadsheet validation within Google Sheets to check data types and expected formats for fields that needed to be entered in known patterns, and Research Software Developer Kevin McElwee implemented automated validation using GoodTables that runs on the data on GitHub and reports any validation errors to a channel in Slack. The automatic validation on GitHub is similar to the “continuous integration” we use on the software we write, which runs automated tests and other checks and reports if anything fails. These kinds of checks are typically set up to be “noisy” when something is wrong and quiet, or even silent, when all the tests pass. As a developer, it bothers me when I see tests are failing and I want to fix things so everything passes; what's more, our software release checklist includes a step to make sure unit tests are passing. We were amazed that the validation report of thousands of “invalid” rows, which had been pre-created in bulk for data entry on a set of manuscripts and not yet made unique, did not bother the project team! In spite of the “noisy” validation errors, they informed us that the reporting was useful and helped them to find and correct problems, sometimes enabling them to correct a problem very quickly after a mistake in data entry.
There were other problems, too. Sharing in-progress data can be tricky; we had to add a prominent warning on the repository telling people not to cite the data yet, since it’s not complete enough for conclusions to be drawn. As the spreadsheet in Google Sheets gets larger, there are performance problems, which may be exacerbated by the validation and lookups. There’s also the concern of working with a proprietary system and APIs for Google Sheets; from the data side, this is mitigated by regularly exporting and synchronizing the data as CSV, but much of the code we’ve written is dependent on those APIs continuing to work the way they do now, so our solutions may be brittle or short-lived.
Next steps?
We don’t have any immediate plans to revisit this approach for supporting data curation in Google Sheets, but there are certainly portions of this work that might be worth generalizing. The script that synchronizes data from Google Sheets to GitHub could be adapted to make it easier for others to set up and use (perhaps with GitHub Actions). Structured data description and automated validation with Frictionless Data and GoodTables are likely to be useful in other contexts; I included Frictionless Data “data package” files in the Shakespeare and Company Project datasets and used them to validate the data before publication, and Kevin McElwee is working on a new tool for Princeton Research Data Service to check large datasets before before deposit. If we decide to revisit the code that automates creation of a structured Google Sheets spreadsheet, I’d love to refactor it so that spreadsheet structure and validation leverages the same data package format we’re using for validation.
Curious and want more information?
- For a write-up of the proposed approach and rationale written before we started, refer to CDH Project Charter — Princeton Ethiopian Miracles of Mary 2019-20.
- https://github.com/Princeton-CDH/pemm-scripts (software)
- https://github.com/Princeton-CDH/pemm-data (data)