Princeton Prosody Archive: Rebuilding the Collection and User Interface
2 July 2018

The following is content associated with a poster presented at Digital Humanities 2018. Full abstract below and also available on the conference abstracts site.
El Archivo de la Prosodia de Princeton: Reconstruir la colección y la interfaz de usuario
El texto que sigue forma parte de un póster que nos presentamos en el DH2018. El resumen completo es abajo y también en el sitio del congreso.

What is Prosody?
Prosody is a historically contingent term. Both the branch of linguistics concerning pronunciation (cadence, pitch, tone) and the aesthetic category of poetic form including versification (meter, rhythm, rhyme, verse forms), prosody sits at the border of science and aesthetics and at the invention of linguistics and literary study as disciplines.
¿Qué es la prosodia?
La prosodia es un término históricamente contingente. Tanto la rama de lingüística que tiene que ver con la pronunciación (la cadencia, el tono) como la categoría estética de forma poética que incluye la versificación (la métrica, el ritmo, la rima, las formas del verso), la prosodia se sitúa entre la ciencia y la estética y la emergencia de la lingüística y el estudio literario como disciplinas.
What is the PPA?
The PPA is a full-text searchable database of ~5,000 HathiTrust-digitized works on prosody published between 1570 and 1923. It collects historical documents and highlights discourses about the study of language, the study of poetry, and how these intersect and diverge. Rather than a static repository of historical data, it compels users to rethink the past and future of organizing, navigating, conceptualizing, and historicizing large amounts of data.
¿Qué es el PPA?
El PPA es una base de datos que permite la búsqueda de alrededor de 5.000 textos completos de la prosodia, los cuales fueron digitalizados por HathiTrust y publicados entre 1570 y 1923. Recoge varios documentos históricos y hace hincapié en los discursos sobre el estudio del idioma, el estudio de la poesía y cómo éstos se intersecan y divergen. En lugar de un depósito estático de algunos datos históricos, el PPA obliga a los usuarios a repensar el pasado y el futuro de organizar, navegar, conceptualizar e historicizar grandes cantidades de datos.
PPA + HathiTrust
All material in the PPA comes from HathiTrust, a partnership of academic institutions that offers a collection of millions of titles digitized from libraries around the world. The PPA teamed with Hathi in 2011 to build an archive dedicated to prosody. We used Library of Congress subject headings to curate a dataset of prosodic titles, and Hathi delivered both the plain text and metadata for ~8,500 fair use monographs. We soon discovered that this method led to many duplicate works due to metadata errors and host library mislabeling.
PPA y HathiTrust
Todo el material en el PPA viene de HathiTrust, una asociación de instituciones académicas que ofrece una colección de millones de obras digitalizadas de bibliotecas alrededor del mundo. El PPA formó equipo con HathTrusti en 2011 para construir un archivo de la prosodia. Usamos los títulos de la Biblioteca del Congreso para crear una base de datos de títulos de la prosodia, y Hathi nos dio ambos el texto sin formato y los metadatos de alrededor de 8.500 monografías del uso justo. Pronto descubrimos que este método resultó en la duplicación de muchas obras a causa de que las bibliotecas anfitrionas habían etiquetado mal los datos y los metadatos.
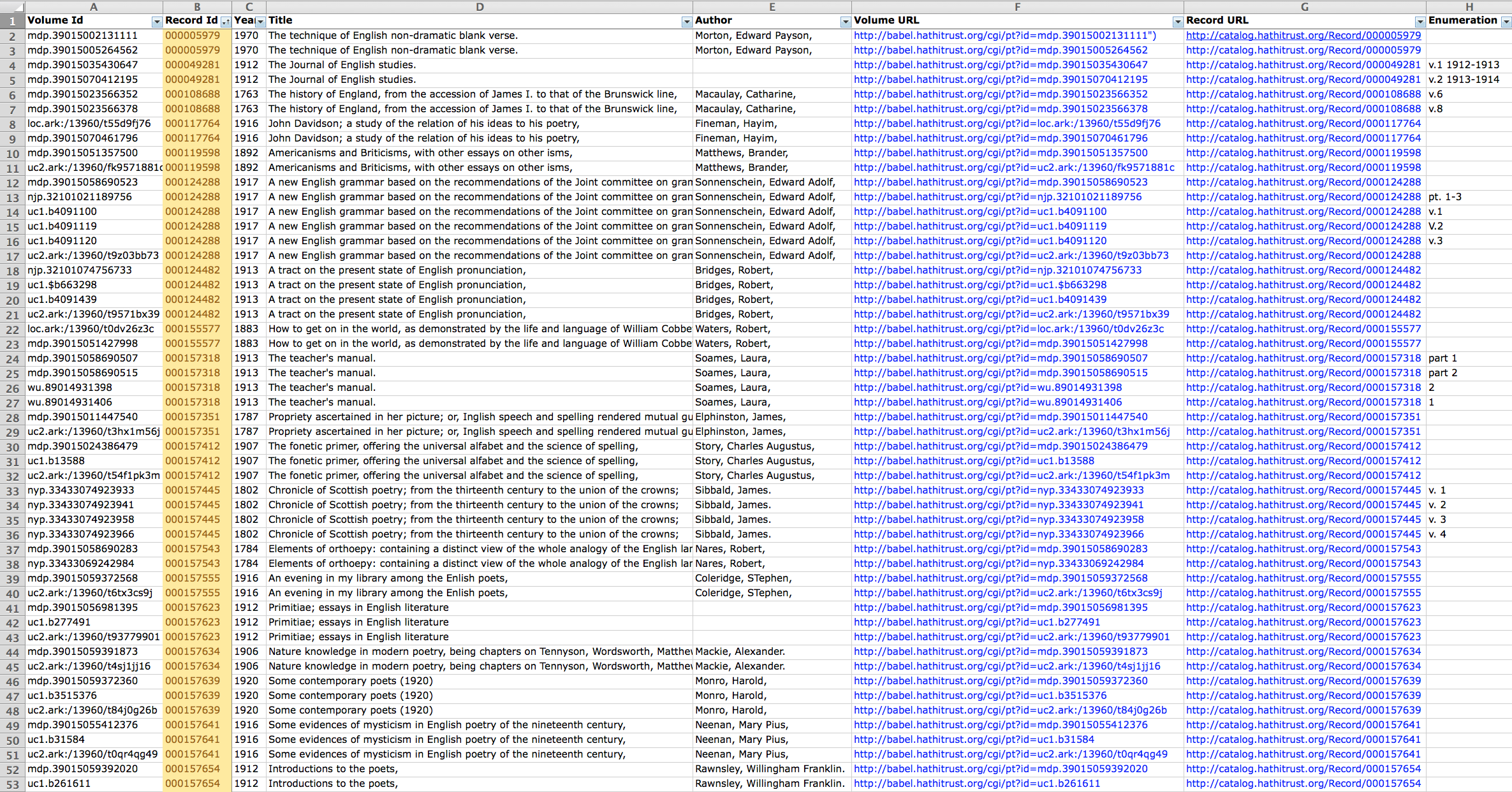
Data Cleaning + Interface
Because duplicate works were skewing search results on our beta-site, we knew we would have to clean our initial dataset. We created a spreadsheet of the metadata, ran a script to cut all duplicate HathiTrust catalog IDs, and painstakingly hand-checked these records for accuracy. This whittled the PPA down to ~5,000 works, showing how many duplicates we were hosting – about 40% of the original file transfer. With a clean, de-duplicated database, we teamed up with the Princeton CDH to create an intuitive user interface with a robust administrative backend. This is crucial for managing HathiTrust works and allows PPA team members to edit metadata, add new works, and even group documents into filterable collections.
Limpiar los datos y la interfaz
Dado que las obras duplicadas distorsionaron los resultados de cualquier búsqueda en nuestro sitio beta, sabíamos que necesitaríamos limpiar los datos. Creamos una hoja de cálculo de los metadatos, usamos una secuencia de comandos para eliminar las identificaciones duplicadas del catálogo de HathiTrust y verificamos los resultados a mano meticulosamente. Este proceso redujo el PPA a alrededor de 5.000 obras, lo cual nos mostró que casi 40 por ciento de la transferencia original contenía información duplicada. Con una base de datos limpia y sin duplicados, nos unimos al CDH de Princeton para crear una interfaz de usuario intuitiva con una soporte administrativa robusta. Esto es crucial para manejar las obras de HathiTrust y permitir a los miembros del equipo de PPA corregir los metadatos, incorporar obras nuevas y agrupar los documentos en colecciones filtrables.
Acknowledgements
Thanks to Dr. Nora Benedict for correcting the translation.
Agradecimientos
Gracias a la Dra. Nora Benedict por corregir la traducción.
Abstract
The PPA collects and displays historical documents prior to 1923, bringing to light little-known texts about the study of language, the study of poetry, and where and how these intersect and diverge. By gathering these documents into one place, the PPA tracks the development of English poetry as a subject of study and shows how this development bridges a variety of discourses, most prominently the rise of linguistic nationalism and linguistic imperialism, but also the advent of stadial history and historiography, the rise of phonetic science and the beginnings of historical linguistics, and a variety of related pedagogical movements that evolve from rhetoric through to elocution and the study of “speech.” The PPA is the only large-scale corpus focused specifically on the study of poetry in the English language. Materials in the archive include grammar handbooks, poetic treatises, versification manuals, elocution guides, histories of literature, editorial introductions, phonetic tracts, and journal articles pertaining to the measure and pronunciation of poetry. By viewing prosody broadly and collecting these materials into one archive, scholars can finally see how the histories of English poetics and linguistics are intertwined, and how the story of English poetic development, alongside the development of historical linguistics, increasingly borrowed, co-opted, imitated, erased, or “civilized” poetic forms from other languages.
Critical attention to these poetic histories and debates are the foundation of Historical Poetics. In addition to scholars of Historical Poetics, the PPA’s audience is teachers of poetry, scholars of poetry, linguists, practicing poets, historians of language, historians of pedagogy, scholars of sound studies, scholars of rhetoric, and lexicographers—all of whom can use the PPA to discover the emergence of a disciplinary term, trace its evolution, or determine its ties to national or political debates. Finally, computer scientists and digital humanists are eager to run textual analytic algorithms on a curated data set that might reveal previously unknown or unexpected results such as the most frequently reprinted poetic example or the most frequently repeated (perhaps without attribution) definition of a particular term.
“Rebuilding the Collection and User Interface,” the PPA’s poster and interactive demonstration for DH2018, showcases the immense data-refinement and metadata-cleaning performed by the PPA since its DH2014 poster session. After launching our new website in May 2018, we are well-positioned to discuss the strengths and struggles of curating and designing an interactive website that relies on HathiTrust Digital Library content. In this way, the PPA sees itself as a project similar to Early American Cookbooks, recently published as a HathiTrust case study in Code4Lib. “Legacy MARC data for early books held in special collections presents particular challenges,” Gioia Stevens writes; “Cleaning and standardizing this legacy data is an essential step in analyzing special collections metadata as a dataset rather than as individual records” (Stevens, 2017). This has proven especially germane to the PPA. From 2015 to 2017, the PPA refined its core collection by eliminating 3,729 duplicate works through a complex and painstaking metadata cleaning process. These duplications were the result of our initial file transfer from HathiTrust and the replicas were skewing users’ search results. The PPA offers a case study in the challenges posed by working with unstandardized metadata. In addition to addressing the benefits and drawbacks of our collaboration with HathiTrust, our poster session aims to highlight how our new interface guides users toward the database’s implicit and explicit arguments, highlights unusual content, and provides pathways for discovery.
- Stevens, Gioia. (2017). “New Metadata Recipes for Old Cookbooks: Creating and Analyzing a Digital Collection Using the HathiTrust Research Center Portal.” Code4Lib 37, http://journal.code4lib.org/articles/12548 (accessed 1 May 2018).