Meet the 2021 CDH Senior Thesis Prize Honorees: William Ughetta
8 August 2021
William Ughetta ’21 creates a benchmarking tool for two databases of historic legal reports.

Each year, the Center for Digital Humanities is pleased to recognize outstanding undergraduate work at the intersection of the humanities and technology with the CDH Senior Thesis Prize. In June, we shared a project on surveillance technologies and health data by Masha Miura (African American Studies), who received an honorable mention in the competition. In July, we highlighted Lauren McGrath (Anthropology) and her award-winning project, “The Side Unseen.” This month, we’re featuring the work of Senior Thesis Prize co-winner William Ughetta (Computer Science).
William’s project, “The Old Bailey, U.S. Reports, and OCR: Benchmarking AWS, Azure, and GCP on 360,000 Page Images,” benchmarked the datasets of legal reports from the Old Bailey Courthouse in London and the United States Supreme Court. “Benchmarking” datasets means to characterize the performance of Optical Character Recognition engines, which convert typed or handwritten printed text into machine-encoded texts.
William told us more about his project and his experience in combining computer science and the humanities.
Tell me about your project.
The goal of my thesis was to benchmark three leading Optical Character Recognition (OCR) cloud services from Amazon, Microsoft, and Google on over 360,000 page images of legal documents. OCR converts images to text and has many applications, such as making a scanned PDF searchable. My thesis revolved around two corpuses of legal records: the Old Bailey in London (1674-1913) and the U.S. Supreme Court and predecessor courts (1754-1915). Over the course of my project, I ran over a million cloud OCR calls on all three services combined, which was possible through generous funding from Princeton. Error rates were calculated by comparing OCR results for the Old Bailey against human transcriptions created for each page by the Old Bailey Online Project. The Supreme Court records, which do not have human transcriptions, serve only as a relative measure of similarity between services. Ultimately, I found that Amazon’s Textract service had the lowest error rate on the Old Bailey dataset, followed by Google’s Vision, and finally Microsoft’s Cognitive Services OCR. This work also led to the creation of the open-source tigerocr tool, which enables reproducible benchmarking of cloud services by handling their different interfaces and presents a unified file format for results that includes coordinates for each text block, line, and word.
Can you describe the digital humanities part of your project?
OCR is invaluable for Digital Humanities research, and it is desirable to measure how accurate these OCR algorithms are. The danger of datasets that are extremely large is that assumptions about the data may diverge from the actual contents, even in carefully reviewed datasets like the Old Bailey. One hundred eighty thousand images can be challenging to grasp. For example, looking at every single image in the Old Bailey for just one second each would take over two days and two hours. If a human worked at this for only eight hours a day, it would take a whole week. Therefore, I created a web-based “explorer” to enable rapid investigation and random access of the whole dataset by allowing humans to search for anomalies using dynamically loaded metrics and to build an intuition for the contents of a dataset without attempting to look at every page, as shown below in the screenshot.
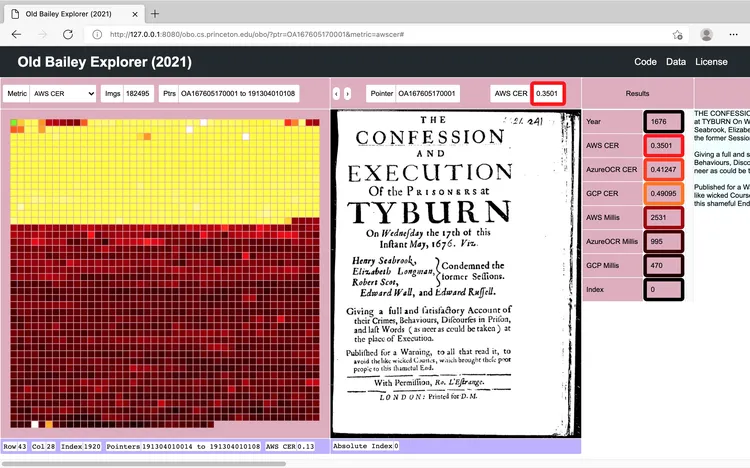
A screenshot of the “explorer” created by Ughetta as part of his award-winning senior thesis project.
What do you think digital humanities adds to your field/major?
Digital Humanities benefits directly from advances in Computer Science technologies. Their interaction culminates in tangible benefits to both fields. For example, measuring Amazon, Microsoft, and Google’s OCR accuracy on the Old Bailey would not have been possible without humanities research at the universities of Hertfordshire and Sheffield that involved creating human transcriptions for over 180,000 page images, a process which spanned eight years from 2000 to 2008. Moreover, advances in reducing OCR error rates on legal documents could directly benefit Digital Humanities research on datasets which do not have human transcriptions available.
What surprised you about doing a digital humanities project?
Some of the largest surprises I encountered were within the pages of the Old Bailey and Supreme Court records (which are called the U.S. Reports). For the Old Bailey, I was most surprised by one case (April 1, 1913 p. 633) where it turned out that the human transcribed a hand-written annotation on the page instead of the original text. In this particular case, the transcriber also introduced an error by combining two names, which were Sydney Charles Dean and David Dealler, as one “S. C. Dean Dealler & E. S. Dean,”, instead of writing “S. C. Dean, Dealler, & E. S. Dean.” Interestingly, the original printed text on the page reads “Verdict (S. C. Dean and Hardy), Not guilty.” For the U.S. Reports, the biggest surprises in the documents were finding maps and patent drawings. More generally, any large dataset is likely to harbor anomalies that can be both challenging and interesting.
What advice would you give a Princeton undergrad interested in doing a digital humanities project?
There are two components to a successful Digital Humanities project: the dataset and the tool. My advice is to pick either one as a motivating research goal and to work towards the other. For example, my research started with the Old Bailey’s trove of human transcriptions, which enabled the OCR benchmark and benefited from creating the explorer. The other approach is to focus purely on the algorithm and then applying it to datasets. Choosing a dataset as a starting point has the benefit of establishing a clear goal of seeing whether or not the code works, which facilitates rapid iteration. Whichever approach is chosen, it’s well worth pursuing and bound to be exciting.
Congratulations to all this year’s honorees! If you are interested in learning more about working in digital humanities, sign up for a consultation with a CDH staff member.