A COS Student in the Geniza Lab
16 November 2021
We asked Richard Cheng ’24 about his experiences working with the Princeton Geniza Project, the CDH’s current research partnership.

Since last academic year, the Center for Digital Humanities and the Princeton Geniza Project have joined together via a research partnership to make the fragmentary texts of the Cairo Geniza more digitally accessible to researchers.
The Cairo Geniza is a cache of about 380,000 fragmentary texts originally found in the geniza chamber of the Ben Ezra Synagogue in Cairo, Egypt. The documents mostly date to the period 950-1250 CE and include letters and legal texts, among other categories.
The Princeton Geniza Project (PGP) is a database under the umbrella of the Princeton Geniza Lab, which was founded in 1985, and which works to advance historical research by transcribing and describing Geniza documents and making them accessible online. The Lab is directed by Marina Rustow, Khedouri A. Zilkha Professor of Jewish Civilization in the Near East and co-PI of the research partnership.
One of the undergraduates working with the Princeton Geniza Project is Richard Cheng (COS ’24). I interviewed him about his experience working with the Princeton Geniza Project and what he has learned.
What led you to join the Princeton Geniza Project?
I’m a COS major, but I’ve always liked humanities courses. I felt that my coursework during my freshman year was very engineering-oriented, and I wanted to try something new during the summer. I was looking around at course descriptions in the Near Eastern Studies department, and I started reading about NES 369, which explores the Cairo Geniza. I read about the Geniza Lab’s work, and I felt that the computational work was really cool. The Geniza Project seemed like a great way to practice the data science which is major-relevant for me, but also try out humanities research.
What is your role in the Princeton Geniza Project, and what is your current project?
I work with data science and computational techniques to analyze our database. I currently create timelines for names that we see in the Geniza documents.
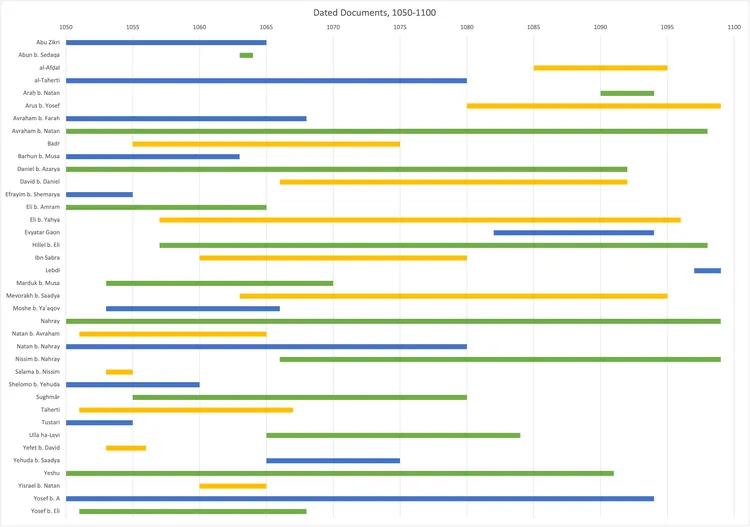
Richard made timelines showing when an individual is mentioned in a Geniza document. This timeline shows the years 1050 to 1100 CE.
What excites you about the Princeton Geniza Project?
Two aspects excite me the most: the context and magnitude of the dataset I’m working with. In my classes so far, most of the data I analyze is pretty far removed from what I actually find cool, so being able to work with the Geniza dataset is very rewarding. In addition, not only are the documents in the Geniza project fascinating, but there are tens of thousands of these documents that I can analyze—I feel like I can parse some pretty cool findings together just because there’s so much to examine.
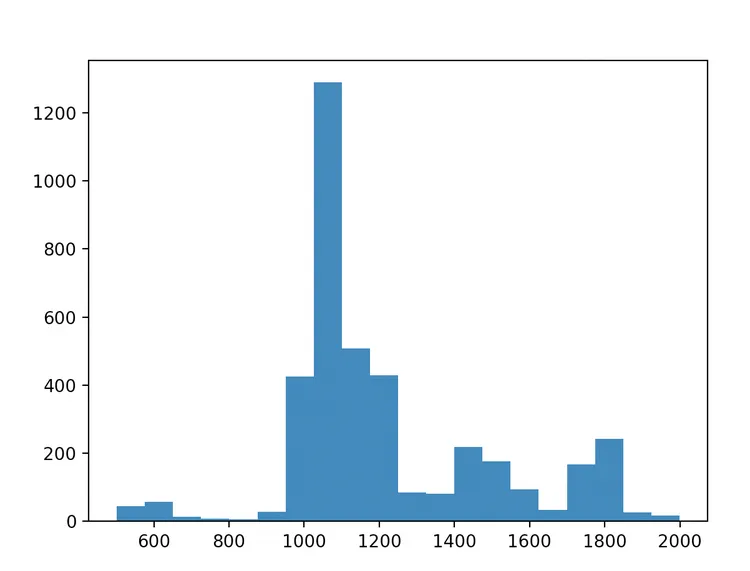
Richard’s histogram shows the frequency of dates found in the Cairo Geniza.
The Princeton Geniza Project has many different people working together (professors, grad students, undergraduates, etc.). What have you learned from this collaboration?
I’ve definitely learned a lot, and I’m humbled and awed by the people around me in the Geniza Lab. In many ways, I’m a bit unusual in this lab: I have never done humanities research, and I major in computer science. Being a witness to the massive breadth of skill in this lab (from multi-language proficiency to historical know-how) just reminds me of what kind of things can be accomplished when hugely-talented people collaborate.
Is there anything that has surprised you while working in the Geniza Lab?
I’ve been surprised by how interesting each individual document or fragment can be. I unfortunately can’t read the languages they’re in, but from reading thousands of the document descriptions, I sometimes feel like I’m reading a book—I didn’t expect that.

Richard’s word cloud shows the top 100 words found in the descriptions of all of the documents in the Princeton database. The frequency of the word is proportional to its size.
What challenges have you encountered while working with the Geniza Lab? What successes have you seen?
I’ve encountered a couple of challenges since joining the lab. First, I’m signing on to a project that’s been in the works for decades, so I was unfamiliar with a lot of the logistics behind how the database works, what kinds of documents we examine at Princeton, etc. In addition, a lot of the data mining I’m trying to do is not the most straightforward work in the world: the Geniza documents were not written in anticipation of me trying to analyze them on my Macbook. I’ve had to be creative to access and compile together data in the Geniza documents. I’ve had some early success with that: I’ve dated documents, located people and placed them on a timeline, and cleaned up components in the Geniza database. And of course, I’m hoping to contribute more at the Lab!
Editor’s Note: This post is part of a series on undergraduate engagement at the Center for Digital Humanities. Check out earlier posts to learn about the work of this summer’s NLP+Humanities Undergraduate Fellow and Princeton Prosody Archive interns.