Old project, new database — a milestone for the Princeton Geniza Project
1 July 2021
Reflections on a major milestone in the Princeton Geniza Project research partnership, including some of the challenges and preliminary insights from migrating the metadata into a relational database.

Editor’s note: On June 24, 2020, the CDH team and the team from the Princeton Geniza Project (PGP) kicked off planning for the CDH-PGP research partnership. The PGP, part of the Princeton Geniza Lab, is a database of documents originally found in the Geniza chamber of the Ben Ezra Synagogue in Cairo, Egypt. Written in Judaeo-Arabic, Hebrew, Aramaic, and Arabic, the documents mostly date to the period 950-1200 and are an indispensable resource for historians of the Middle East, scholars of Jewish studies, and others.
In this post, Rebecca Koeser, CDH Lead Developer and Co-PI (with Marina Rustow) of the CDH-PGP research partnership, reflects on a major milestone in the now year-long collaboration and previews the partnership’s second year.
At the end of May, after many months of work (including at least 45 team meetings since our initial chartering meeting in June 24, 2020; 120 GitHub issues; 357 Asana tasks; and 7,772 Slack messages and 2,528 reactions across 4 channels), we migrated the Princeton Geniza Project (PGP) metadata from a massive Google Sheets spreadsheet (along with a few ancillary spreadsheets defining languages and scripts, libraries and collections, and demerged records) into a shiny new relational database. This was a very timely migration, since the metadata spreadsheet had by this point grown so large — 19 columns and 30,786 rows — that it was quite slow to load, and some of the student researchers on the project could no longer work with it. The new database currently contains 31,043 documents; 30,098 fragments; 2,482 tags; 765 scholarship records; and 6,343 footnotes linking scholarship records to documents.
PGP is significantly different from past CDH research partnerships in terms of the age of the project and thus the amount of data we have to work with, even though the metadata we’ve been focusing on in this phase of the collaboration is only one piece of the total PGP data (for more details about this long-running project, read about the history of the Geniza Lab). In our past collaborations, we were working on newer projects, and sometimes there was not yet enough data to do interesting work. At times this led to development and data work alternately being blocked waiting on each other: the project team would be waiting for their new database interface to do data work, and then development would be blocked while they started actually using the database and adding information. This is one of the problems that led to the creation of our dataset curation grants (now data fellowships), which tackle data work independent of and prior to collaborating with the CDH Development and Design Team. Because the PGP is an older project, one challenge we took on as part of the data import was parsing out historical input information that documented who added an entry or made a major revision, and when. Now that this historical information is in a more structured format, we can easily visualize the shape of the PGP over time.
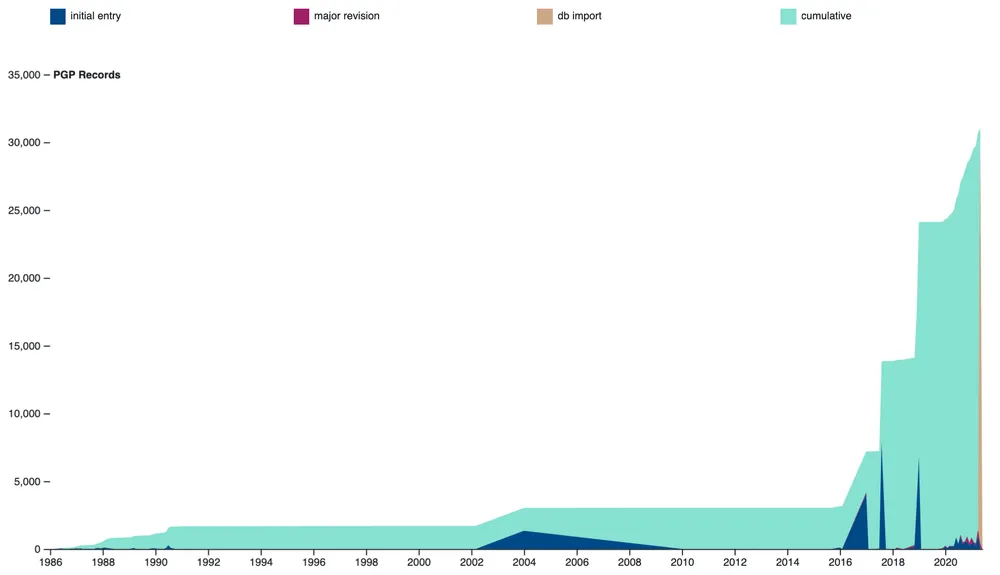
Documents in PGP over time, based on historical information imported into the new database. The jump in 2016 shows the shift from slow and painstaking transcription to description.
Moving data from a spreadsheet into a database requires you to be more specific and consistent about how you are modeling and structuring your data. The metadata spreadsheet in Google Sheets had a single “Library” field that had a short abbreviation or name for the library or institution that holds the fragment — but in some cases, this was actually a collection name. After some deliberation and revision, we now represent this information by collections in the database. Some collections are associated with libraries; some libraries, like Cambridge, have multiple collections, while other libraries don’t have collections; but there are also collections that are not associated with a library. Having collection and library information in a more structured form opens up new avenues of inquiry, such as analyzing how the documents in PGP are distributed geographically and institutionally.
Challenges
One of the bigger challenges of moving from spreadsheet to database, or moving “from 2D to 3D” as Marina Rustow described it, is the change in how we are modeling Documents and Fragments. There is a long-standing debate in the Geniza scholarly community about whether to prioritize fragments (i.e., the physical objects retrieved from the Cairo Geniza) or documents (texts written on one or more fragments). A relational database lets us model them both and connect them, but requires us to decide which pieces of information belong where. And because the Django Administrative interface is built on top of the database, editing efficiently requires a basic understanding of that data model and where to edit which information. The PGP has always been document-centric, but the metadata spreadsheet was not quite set up to match that: documents that occurred on multiple fragments were represented by multiple rows, one for each fragment, with a special “join” column to document that they were connected. Each row of the old metadata spreadsheet includes fields to describe fragments, such as shelfmark, library, and URL alongside columns describing the document, such as the description, tags, editor, and language. In contrast, in our new relational database, we split this information across different tables.

A document (PGP ID 8862) in the metadata spreadsheet.
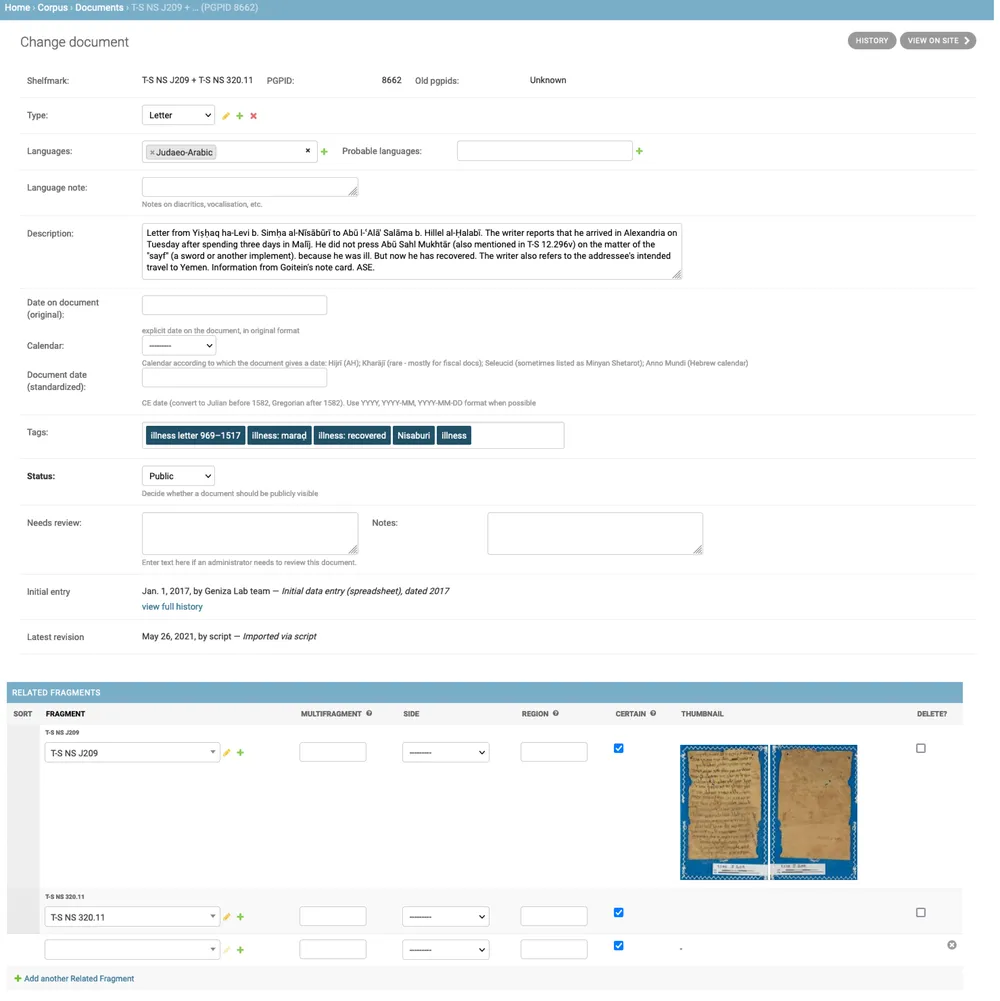
The same document (PGP ID 8862) in the Django admin interface. Documents are linked to fragments; a combined shelfmark is generated from the list of associated fragments.
The new relational data model makes it possible to handle documents that occur on multiple fragments more elegantly. In the spreadsheet, the different parts of a join would have either the same description repeated, or references to the main document by PGP ID or fragment shelfmark. In the database, a document can be linked to multiple fragments with order specified — and we refined this even further to add a “certainty” flag, making it possible to connect a document to a fragment that might be related, but that is not definitely part of the same text. These fragments are linked to the document, but are not included in the combined shelfmark.
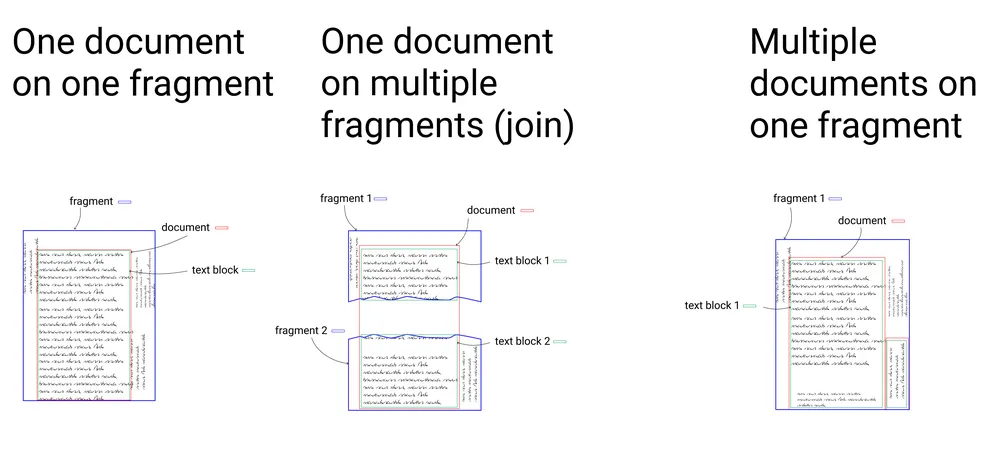
Created by Gissoo Doroudian with input from Rebecca Sutton Koeser
Data model diagram to help team members understand the new structure. Not included in this diagram: multifragments, multifolio documents, and uncertain joins.
In hindsight, I think the shift in how documents and fragments are stored may be the biggest challenge for the project team to adjust to. In database speak, I modeled the connection between documents and fragments as a “many-to-many” relationship — a document can be written on more than one fragment, but fragments may also contain multiple different documents. To avoid repetition and redundancy, urls for viewing a fragment or accessing its images are stored on the fragment. When editing or viewing a document, we want to include the images of the fragment (if any are available); but every document on a fragment will use the same set of images, and we want to manage those links in one place. To the project team members, it was not immediately obvious that they needed to edit information about the fragment (including view and image links) in a separate place from the document, since they were used to editing all of that information in a single row in the spreadsheet.
As part of the import, we parsed information editor and translator information into scholarship records and footnotes linking specific sources to the documents they are about. It was challenging to parse: citations and notes that were reasonably easy for humans to make sense of and looked fairly regular at first glance turned out to have quite a variety of formats. Even after multiple rounds of testing and refining this portion of the import code, we still ended up with a lot of cleanup that is being handled by the project team. However, I believe it is worth the effort: this newly structured information makes it possible to explore and analyze the network of scholars and documents within the PGP. I used that data, in combination with historical input data, to generate a visualization of every document in the PGP that shows the number of people who have worked on it (whether formal scholarship or data work), and makes it possible to highlight the specific documents worked on by the top 15 contributors.
Highlight by top contributors
Every document in the Princeton Geniza Project , ordered historically. Documents are colored by the number of contributors (data editors or scholars) who have worked on them. Scroll to see all; use ⤢ to view in full screen.
Another challenge we encountered was the need to optimize admin searches and data downloads to handle the amount of data already in the system. On other projects, it usually took a while before teams had enough data to cause performance problems — but in this case, very early on we discovered that the Django admin search broke when searching for shelfmarks that occur in multiple combinations of long joins. We solved that by replacing the default Django database search, which is known to be inefficient, with a custom Solr search (a solution we also used for the Shakespeare and Company Project, but at a much later point in the project!). We also needed to provide CSV data exports for database content, both to give the team access to the information in a familiar format and to keep the current PGP site synchronized with changes made in the database. Unfortunately, the first implementation for a document CSV download didn’t take into account that any inefficiency in the code gets magnified when you’re running it 30 thousand times! Fortunately, after spending time on profiling and refactoring, I was able to optimize the document download so that the entire set can be downloaded in a reasonable amount of time, and smaller subsets download very quickly
What’s next?
The PGP team is busy working on the data in the new database: starting to make better use of the new structured fields like languages and dates, uncovering bugs we didn’t catch while testing the import, cleaning up oddities caused by the import, and adding new records. There’s also a Handwritten Text Recognition Project running in parallel to the PGP-CDH collaboration, which we hope will generate new and restructured transcriptions which will be fed into the database at some point.
On the CDH side, we’re supporting the data work by answering questions, fixing bugs, and implementing small improvements as we can while we shift our focus to other projects for a bit. But I’m looking forward to circling back to this later on this summer to plan out the next phase of work — including figuring out how to migrate and integrate other pockets of PGP data that have been siloed (transcriptions, images of early Geniza scholar S.D. Goitein’s index cards) and building out a new frontend based on the database.
Thanks to Camey VanSant for feedback and edits. Thanks also to Gissoo Doroudian for brainstorming with me how to make my documents + contributors visualization more engaging and more usable on mobile (I did not have time to implement all of her suggestions in this version; the deficiencies and limitations in the visualization are mine alone).