Event Recap: New Languages for NLP Workshop I
22 July 2021
The series aims to expand natural language processing (NLP) resources to low-resource and historical languages.

[Editor’s note: This post is part of our series on multilingual DH at the Center for Digital Humanities.]
On the week of June 21, 2021, the CDH held the first workshop in the New Languages for NLP: Building Linguistic Diversity in the Digital Humanities series, a National Endowment for the Humanities Institute for Advanced Topics in the Digital Humanities. The series aims to expand natural language processing (NLP) resources to low-resource and historical languages by empowering teams of scholars to annotate linguistic data and train statistical language models using cutting-edge NLP tools. The series is co-directed by CDH Associate Director Natalia Ermolaev, and Andrew Janco, Digital Scholarship Librarian at Haverford College, and includes participants working in ten languages: Classical Arabic, Old Chinese, Kanbun, Kannada, Ottoman Turkish, Quechua, Russian, Tigrinya, Yiddish, and Yoruba. This first workshop focused on corpus annotation and introduction to linguistic data.
The workshop kicked off with a discussion of NLP and humanities scholarship. Drawing from pre-assigned readings on topics like linguistic diversity and ethical issues in NLP, participants contributed by including perspectives from their languages. After the large-group discussion, participants were split into breakout rooms to continue the conversation.
Tuesday marked a gateway into the more technical side of the workshop. Toma Tasovac, Director of DARIAH-EU, introduced linguistic data standards, corpus annotation, and annotation development cycles. Following comments and questions, Quinn Dombrowski, Academic Technology Specialist in the Division of Literatures, Cultures, and Languages, and in the Library, at Stanford University, conducted a practical session on using INCEpTION for annotating the corpus.
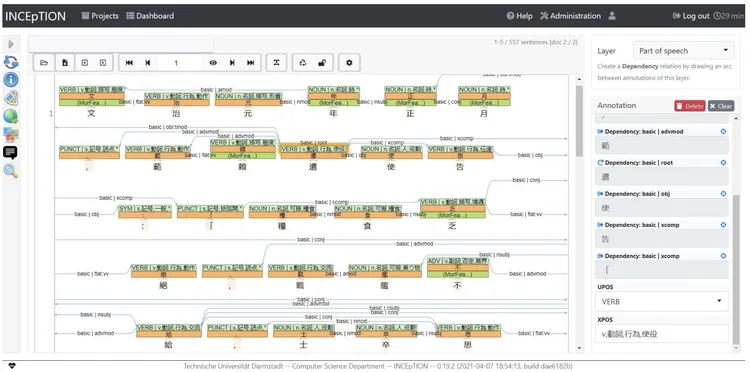
Example of Kanbun text annotations using INCEpTION
As attendees were getting more comfortable using technical tools, the third day began with Tasovac leading a session on spaCy, a free open-source library for NLP in Python. The session both included how a machine learning model is different from the rule-based system and covered details of the processing pipeline. Then, Janco introduced Cadet, a web application designed for this workshop to facilitate the entire annotation process. Cadet not only made the workshop accessible to participants with no coding experience but also provided a roadmap of the full annotation process.
Most of the next day was spent diving deeper into Cadet and addressing questions from individual language teams. One challenge that arose: sentencizer (splitting text into sentences) did not work particularly well for the Classical Arabic team as the language does not contain any punctuation or other markers between sentences. For the second half of the session, we were joined by Richard Eckart de Castilho, project lead of INCEpTION, who addressed some specific concerns. Topics included customizing the annotation layers and adding external recommenders to the model.
The final day commenced with David Lassner, doctoral researcher in Machine Learning at the Technische Universität Berlin, moderating a discussion session on connecting NLP and humanities research. In addition, participants were split into teams for a pattern-matching game to find stage directions in works of drama. We got together at the end to discuss the approaches used and best practices. Being the last day of the first workshop, the rest of the time was spent sharing reflections on the week. In addition to gathering feedback for future workshops, instructors outlined how to prepare and what to expect for the workshop in January.
Although the first workshop of New Languages for NLP has concluded, the project has just started! Over the next few months, participants will continue annotating their corpus and meeting with the instructors every month. The second workshop is scheduled for January 2022. We hope to be able to welcome participants to Princeton in person!
Anubhav Sharma is the undergraduate instructor for the New Languages for NLP workshop. He is currently majoring in Computer Science and Mathematics at Haverford College. He loves to work on digital projects and in addition to the technical aspects of the workshop, he enjoyed interacting with humanists from different languages!

Any views, findings, conclusions, or recommendations expressed in this post do not necessarily represent those of the National Endowment for the Humanities.