Award-Winning Project Explores Optical Document Recognition (ODR) in Princeton Prosody Archive
16 July 2025
James Zhang ’25 captured this year's CDH Senior Thesis Prize for his research.

James presents his work at The Ends of Prosody Conference at the CDH in May 2025. (Photo: Carrie Ruddick)
Have a lot of character flaws—in your scanned documents, that is?
CDH Senior Thesis Prize winner James Zhang ’25 can help.
The computer science major from Basking Ridge, NJ, began exploring the limitations of Optical Character Recognition (OCR) as a junior in a digital humanities independent work seminar led by Brian Kernighan, the William O. Baker *39 Professor in Computer Science and a member of the CDH Executive Committee. His junior project used Large Language Models (LLMs) to “reconstruct” the original text from flawed OCR output, using the Princeton Prosody Archive (PPA) as a case study. For his senior thesis, James expanded his approach by incorporating Large Vision-Language Models (LVLMs) to analyze the visual elements of historical documents. The result was MetaScribe, an open-source tool he developed to help librarians and researchers get more from archives like the PPA.
His innovative work earned him both the CDH Senior Thesis Prize and the Princeton University Library Award at the 2025 Princeton Research Day. In 2024 he had received the Campus Impact Award.
We recently asked James to share more about his work.
Tell us a little about your winning thesis. What problem did you identify, and how did you work toward a solution?
My thesis explores how large vision-language models (LVLMs) can support Optical Document Recognition (ODR) in libraries; specifically, how they can help extract and generate (richer) metadata from scanned documents. I built an open-source tool called MetaScribe that leverages LVLMs to extract information from scanned documents and create metadata based on customizable fields. It is designed to scaffold the metadata creation process, offering a flexible starting point that archives and libraries can adapt to their own needs. The project includes both a technical evaluation of model performance across tasks and a broader discussion of implementation: how to integrate AI responsibly into library workflows, ensure transparency, and support—rather than replace—the expertise of human catalogers.
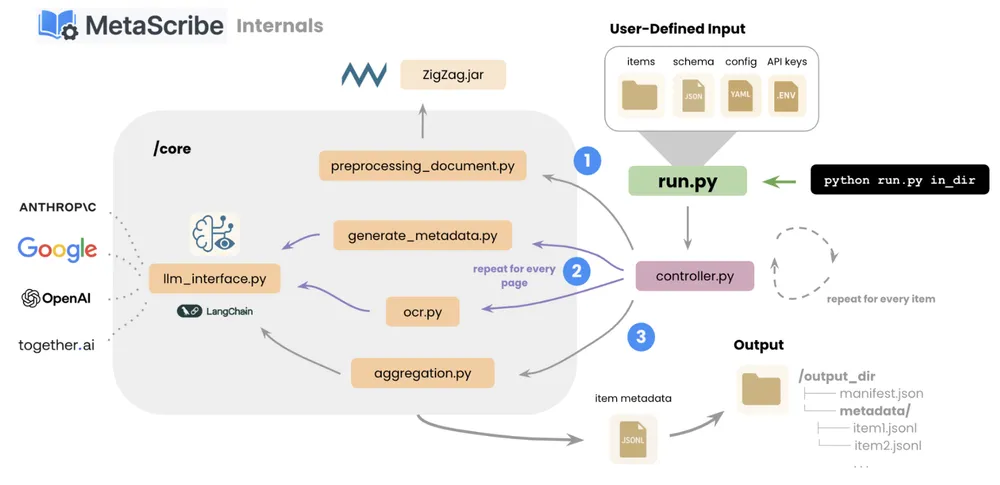
A visual diagram of the MetaScribe extraction process.
The Princeton Prosody Archive, the flagship project at the Center for Digital Humanities, figures prominently in your project. How were you first introduced to the Center for Digital Humanities?
This project grew out of work I began in my junior spring, when I was first introduced to the CDH. I took Professor Brian Kernighan’s “Digital Humanities” independent work seminar, where Dr. Wouter Haverals (Perkins Fellow and Associate Research Scholar) and Dr. Mary Naydan (DH Project Manager) from the CDH served as teaching assistants. Through them, I was introduced to the Princeton Prosody Archive (PPA) and learned about the broader challenges the CDH faced. Wouter and Mary first pointed out that the Optical Character Recognition (OCR) provided by vendors like Gale and HathiTrust was often subpar, which limited the archive’s usability. That semester, we tackled the post-OCR correction problem, asking: If all we had was the raw OCR text, could we reconstruct the correct transcription? We found that purely textual large language models (LLMs) could, surprisingly, perform this task quite well.
But through this process, we started questioning the framing: was “recognition” really the main problem? Browsing the PPA, with its visually rich and structurally complex pages, it became clear that even perfect OCR often flattens the very elements that give documents meaning. What we needed wasn’t just more accurate transcriptions: it was better representation.
That tension, between treating documents as plain text versus as visual objects imbued with semantic structure, became the heart of my thesis. Playing with the PPA’s search interface made the issue feel concrete: there was all this visual richness, but little way to search for it. It created what we felt like an “illusion of find.”
And so with the rise of LVLMs, new possibilities opened up. Their general capabilities, from layout and chart understanding to visual-text interpretation, map naturally onto tasks libraries care about, particularly metadata creation, which remains a human labor-intensive process. We saw that LVLMs could offer a way to bridge the gap between raw document images and meaningful, searchable representations. With a richer metadata backbone, we can then enable more powerful discovery and computational scholarship.
What we needed wasn’t just more accurate transcriptions: it was better representation.

Left: James with his thesis advisor Brian Kernighan. Right: James, Wouter, and Mary at Princeton Research Day 2024.
What challenges did you overcome?
Many moments over the year, it was tempting to jump straight into building something based on my own assumptions about what the PPA (and libraries and archives more broadly) need, despite having no prior experience with the PPA or the metadata creation process. One of the greatest challenges was resisting this urge.
By adopting as few assumptions as possible, I spoke directly with staff in the CDH and University Library broadly (Special Collections, Digital Scholarship, and Research Data)— all of whom shaped how I thought about metadata, digitization, and what counts as “useful” information. Through their iterative feedback, I identified a few key themes that ultimately shaped my thesis’s system design.
What was one exciting takeaway from your project?
Out-of-the-box LVLMs already show promising performance, making it possible for archivists and librarians to start experimenting with their own collections—and even generate useful metadata right away.
Cost, speed, and performance trade-offs matter at scale. For example, the most accurate model I tested (OpenAI’s o1) wasn’t always the best choice in practice. In fact, a smaller and cheaper model (Google’s Gemini-2.0-Flash) proved ideal for many tasks, running 20 times faster and costing 680 times less per page than o1, while still delivering strong results. This suggests that even institutions with limited resources can leverage AI tools today, not just those with large budgets.
What inspired you to continue your work in DH for your senior thesis?
Since learning about the center last year, I’ve been continually inspired by the wonderful projects the CDH supports. Digital humanities, as a field, brings together a unique blend of technical innovation and deep engagement with human history and culture.
What pushed me in particular was seeing how genuinely interested the staff at the CDH and PUL were in my research, even when it was just a proposal. Over time, I recognized that my work could actually support researchers and librarians in a meaningful, lasting way —and that sense of purpose has carried me since.
What was your experience as a computer science student working with humanists? How did your involvement with the CDH complement your education in computer science, or how did it challenge it?
In many computer science classes, there’s usually a “right” answer. It is not quite so in the digital humanities—working with humanists at the CDH opened my eyes to the sheer messiness and ambiguity of real-world problems. I learned to make decisions based on practical tradeoffs, which pushed me to become more adaptable, thoughtful, and collaborative in my approach to problem-solving.
We know you won a Schwarzman Scholarship and plan to study global affairs at Tsinghua University—congratulations! How do you see your work at the CDH connecting to your graduate study and future career?
My work at the CDH taught me the value of admitting what I don’t know and deferring to the expertise of others. I learned to ask questions first, build second. As I move into global affairs (in the context of ensuring safe AI development) at Tsinghua, I’ll carry that same humility and collaborative spirit to build bridges across fields and cultures.
I learned to ask questions first, build second.
What’s your advice to other computer science students interested in the intersection between CS and the humanities?
Channel an open mind! Resist the urge to assume you know what humanists need. Don’t be afraid to aggressively chase what you don’t know—continually immerse yourself in the inevitably messy (and hopefully unfamiliar) data and listen more than you talk.